The programming language “immediate C” or iC is a declarative, event-driven extension of the procedural language C – useful for machine control, robotics and for dealing with events generated in a GUI.
iC utilizes the syntax of C to give meaning to statements that have no semantic support in C. In addition to standard variables, which are modified by the flow of instructions, iC provides so-called ‘immediate‘ variables, whose values are updated, whenever a change of input calls for an immediate change in output. An efficient Data Flow technique implements this strategy.
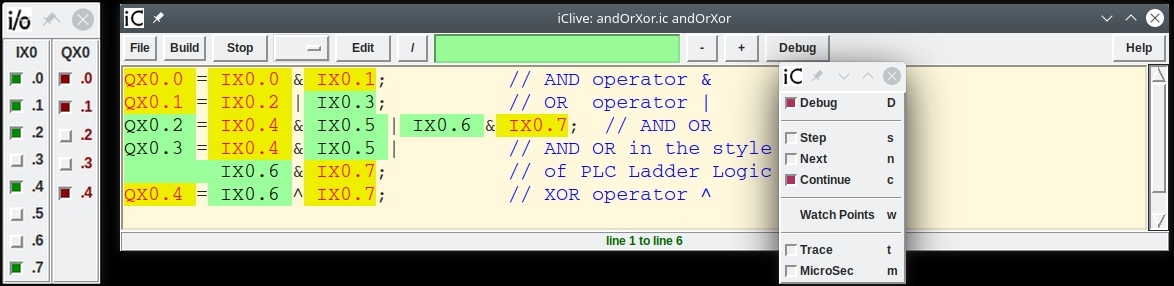
iC provides programmers with built-in operators, whose function is closely modelled on integrated circuits. The name iC is a reminder of this fact. Logical AND, OR, EXCLUSIVE-OR and NOT as well as D flip-flops, SR flip-flops, shift registers and many others are implemented in such a way, that their use in iC follows the same design rules, which apply to their hardware counterparts. These rules have led to a well-developed hardware technology, whose effectiveness is demonstrated by the success of today’s complex computer hardware. Particularly the concept of clocked functions plays an important role in the language iC. It gives the same protection against timing races in iC programs, as it provides for hardware IC designs. But iC is not a hardware description language nor a simulation language – it provides the functionality and some of the speed of field-programmable gate arrays with a language, which is pre-compiled into straight C code, which is portable and produces efficient machine code.