This blog describes a set of hooks for GIT, which do real version number incrementing when a file that contains a well-formed $Id string is committed. These hooks have absolutely no effect on files not containing a $Id string. A major feature of these hooks is the fact that they are compatible with GIT branch names and store the branch name from which a file is committed in the $Id string.
The format of a clean well-formed $Id <version> string for these hooks is very similar to those used by RCS/CVS/SVN, namely full stop separated pairs of major and minor versions:
* the first string is the major version number in the master branch.
* even strings are consecutive version numbers in the branch.
* odd strings identify branches (branch names or numbers).
The following are a sequence if $Id strings for the file xx.c after a series of 3 edit/commits in the ‘master’ branch followed by 2 edit/commits in branch ‘bxx’ followed by an edit/commit in branch ‘byy’:
$Id: xx.c 1.1 $
$Id: xx.c 1.2 $
$Id: xx.c 1.3 $
$Id: xx.c 1.3.bxx.1 $
$Id: xx.c 1.3.bxx.2 $
$Id: xx.c 1.3.bxx.2.byy.1 $
This is how the $Id text is stored in the GIT archive after each commit. After ‘smudging’, which is applied to the file in the working directory after a git commit/fetch/checkout, the last $Id would look like this:
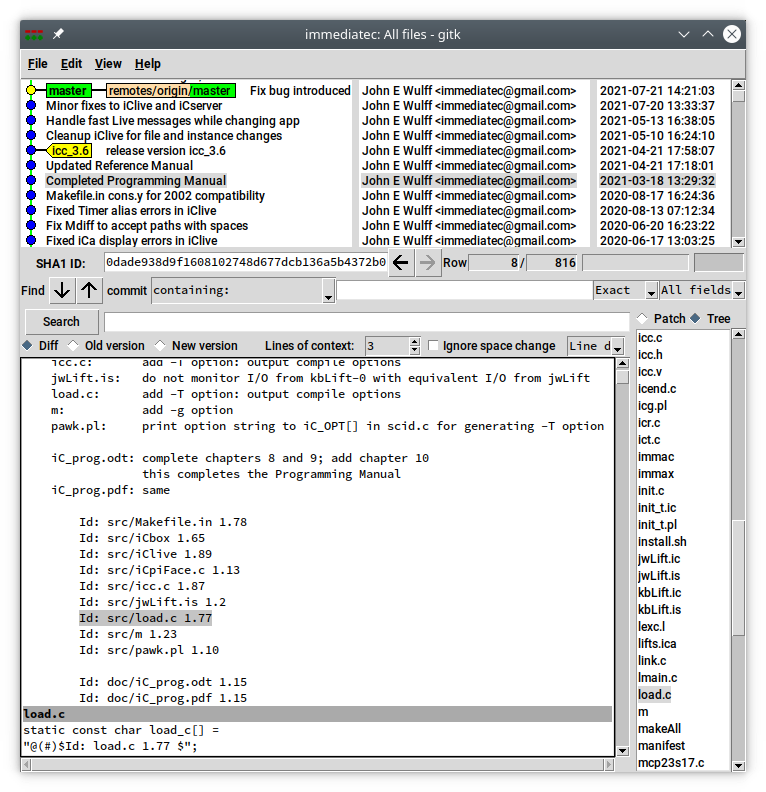
$Id: xx.c 1.3.bxx.2.byy.1 30e82ef 2016-04-03 14:48:24 +1000 Joe Blow $
This automatic method if $Id keyword expansion shows the current file name, the branch in which an instance of a file was edited and its individual version number within that branch. This information is embedded in the text of a file in a manner, which is fully compatible with GIT. After smudging, the $Id also shows the commit SHA-1, the date and the author of the file instance. The $Id information in each file provides an independent file oriented view, which can be regarded as a belts and braces approach to handling files in GIT.
To support an alternative workflow, that many programmers are used to I propose the following Perl and Bash scripts for GIT automatic $Id keyword expansion (gaIdke), which act together to increment and update version numbers in $Id strings in a similar way to that which is carried out in RCS, CVS or SVN. These scripts have no effect on any sources which do not contain a $Id string. GIT will act normally in every way for these sources. Only when a $Id string is placed in a source will the automatic incrementing of version numbers come into effect (this is similar to RCS etc).
The following Perl and Bash scripts make up hooks of the the gaIdke package:
gaIdke.clean
remove git SHA-1 hash, iso commit date and author name before the final $ of a correctly smudged $Id string, which is ‘$Id: <filename> <ver> <hash> …$’. <filename> and <ver> can be any non white-space characters except <filename> and <ver> may not start with a $ to prevent a Heisenbug. <hash> is any length word consisting of lower case hex digits.
Only $Id strings that contain a white-space separated <hash> in the right place are cleaned. This makes sure that any $Id strings imported from legacy repositories are not modified.
‘clean’ is called by numerous git operations, in particular by ‘git add’, ‘git status’ and ‘git diff’. This ensures that files containing smudged $Id strings compare correctly with committed versions.
gaIdke-pre-commit
Obtain the list of files currently being committed (staged) and not modified since they were added to the index (not dirty). Exclude files being deleted. Back up each file in this list and rewrite the file – scanning for $Id lines.
If a $Id string is found, increment the last number in <ver> of any $Id: <path> <ver> line in the file and replace any text between <ver> and a final $ by one space. <path> is obtained from a ‘git diff –name-only –diff-filter=d –cached’ command, which is the list of files staged for commit excluding files to be deleted. If a file has been renamed, the new path is written in the $Id: string. The file will be committed with the updated clean $Id line.
For a new file yy.c containing “$Id$” only, gaIdke.pre-commit expands this to “$Id: yy.c 1.1 $” to start the process.
The above applies if the commit is executed in the master branch. Special handling applies if the commit is executed in any other branch. If the file was never modified in this branch (say ‘bxx’) and was originally generated in the master branch and is the 3rd version of ‘xx.c’ the following Id applies: “$Id xx.c 1.3”. After this file has been edited in this branch ‘bxx’ and committed, ‘pre-commit’ will generate a new Id incorporating the branch name ‘bxx’: “$Id: xx.c 1.3.bxx.0”, which will be incremented to “$Id: xx.c 1.3.bxx.1”. After another edit and a commit, this would become “$Id: xx.c 1.3.bxx.2”. If you now move to another branch (say ‘byy’) and edit the same file in that branch and commit, the $Id string would become “$Id: xx.c 1.3.bxx.2.byy.1”.
A new file zz.c in branch ‘bxx’ will start with “$Id: zz.c 1.1.bxx.1”.
To avoid long $Id strings with branches, it is advisable to use short branch names when using $Id: keyword expansion.
Finally append the path and modified version to .gitSmudgeList. This list is stored for use by post-commit for a ‘checkout’ and ‘smudge’ of modified files. The information in .gitSmudgeList is also used by ‘prepare-commit-msg’ to pre-format a list of $Id incremented files as a tail for the commit message. This is not optional because ‘smudge’ uses this information in the log to find the right commit for this version of the file.
If no $Id string is found when scanning a file in pre-commit, the backup of the file is restored and that path is not recorded in .gitSmudgeList. This means the file will not be smudged in post-commit and because its modified date is not changed here or in post-commit, the file will not trigger a subsequent ‘make’. The operation is completely transparent to GIT for this case.
$Id keyword expansion can be suppressed by placing the string $IdBlockFurtherExpansion$ after an initial $Id keyword line, which will be expanded and before any line containing $Id$ or $Id: <path> <ver> $, which would otherwise be expanded. This is only required for files like this one describing $Id features.
gaIdke-prepare-commit-msg
Obtain the list of files which have been updated with an incremented <ver> in pre-commit from .gitSmudgeList. Each smudgeLine in .gitSmudgeList is formatted as follows by pre-commit:
<path> <ver>
or <path> <ver> <- <previous_filename>
These lines preceded by ‘ Id: ‘ are added before the first comment of the new commit message. No lines are added for any files in the commit, which do not have a $Id string.
gaIdke-reset
To recover modified files containing $Id lines after aborting a commit by completely clearing the commit message, execute ‘.git_filters/gaIdke-reset’ (an empty commit message aborts a commit in GIT).
At that point, the files in the working directory which have been staged will have cleaned and incremented $Id lines, but there will also be a backup copy of each of these files with the suffix .gaidke. To recover the state before the aborted commit, each of the .gaidke backup files is moved back to the original working file, but only if the working file has not been changed since the aborted commit. Also, the recovered files are staged again with ‘git add’.
If a staged file has been changed and a .gaidke file for it exists, only the $Id line must be copied back to that file and staged again.
Files that are staged to be deleted can be ignored. They have already been removed from the working directory.
gaIdke-post-commit
Obtain the list of files that have been updated with an incremented <rev> in pre-commit from .gitSmudgeList. Execute ‘git checkout HEAD’ to call smudge so the file in the working directory will have a $Id with an incremented <rev> followed by the commit hash, the author commit date and the author name. Also, remove the backup file here.
gaIdke.smudge <p1>
<p1> path of the file to be smudged relative to GIT base.
Insert git SHA-1 hash, iso commit date and author name before the final $ of a clean $Id string, which is ‘$Id: <filename> <ver> $’. <filename> and <ver> can be any non white-space characters except <filename> and <ver> may not start with a $ to prevent a Heisenbug.
To find the right commit for this file and version in case this script is called by git checkout for a non HEAD commit, the whole log has to be scanned for ‘Id: file ver’ inserted by gaIdke-prepare-commit-message.
Only ‘clean’ $Id strings are smudged. This makes sure that any $Id strings imported from legacy repositories are not modified.
‘smudge’ is only called in ‘git checkout’ and indirectly in ‘post-commit’, ‘fetch’ and ‘clone’.
gaIdke.post-checkout
Called after ‘git checkout’ to correct possibly incorrect smudge values if HEAD had not been correct for ‘checkout’. The same script is used for the ‘post-merge’ hook.
gaIdke.post-merge <p1>
<p1> Flag indicating whether the merge was a squash-merge.
Called after a ‘git merge’ or a ‘git pull’ – I presume because ‘git pull’ is equivalent to ‘git fetch; git merge FETCH_HEAD.
The problem is when ‘smudge’ is executed after a ‘git pull’ for the modified files, HEAD has not been adjusted yet to the position after the rebase. This is the situation after ‘git fetch’:
d–e <– FETCH_HEAD
a–b–c <– HEAD
This is the situation after the merge at which point modified files are checked out and smudged incorrectly because HEAD still points at the old commit and ‘smudge’ uses ‘git log’, which starts looking at HEAD and thus cannot find the commits d’ and e’ which contain the details for the modified files.
d’–e’ <– FETCH_HEAD
/
a–b–c <– HEAD
This is the situation after files have been checked out and a rebase has been done. At this point, ‘post-merge’ is called and the newly fetched files can be smudged correctly.
a–b–c–d’–e’ <– HEAD
^————— ORIG_HEAD
gaIdke.activate
Execute ‘.git_filters/gaIdke-activate’ after cloning a project containing ‘Automatic GIT Id Keyword Expansion’ gaIdke, to place the correct symlinks in .git/hooks, and write a [filter “gaIdke”] entry in .git/config.
If ‘.git_filters/gaIdke-activate –global’ is executed also copy all the files in ‘.git_filters’ to ‘/usr/local/share/git_filters’, symlink the hooks to them and write a global [filter “gaIdke”] entry in ~/.gitconfig.
This way you can use ‘Automatic GIT Id Keyword Expansion’ in other GIT projects, although you need to copy all the files in ‘.git_filters’ to another project if you want to publish it.
To automate this activation I have placed the following code towards the end of every ‘configure’ script for projects containing the gaIdke hooks. This means GAIDKE is active as soon as the configure script is run for a newly cloned project.
# do gaIdke-activate if cloned GIT with gaIdke – CHANGE from autoconf
git_base=$(git rev-parse –show-toplevel 2> /dev/null)
if [ -n “$git_base” \
-a -f “$git_base/.git_filters/gaIdke-activate” \
-a ! -e “$git_base/.git/hooks/post-checkout” \
-a ! -e “$git_base/.git/hooks/post-commit” \
-a ! -e “$git_base/.git/hooks/post-merge” \
-a ! -e “$git_base/.git/hooks/pre-commit” \
-a ! -e “$git_base/.git/hooks/prepare-commit-msg” ]; then
. $git_base/.git_filters/gaIdke-activate
fi
Environment:
export GAIDKE=verbose # causes some filters to output extra debug output.
GIT automatic $Id Keyword Expansion has been implemented in the immediate C project at https://github.com/JohnWulff/immediatec and can be copied from there. Simply copy the folder .git_filters to your own project Git base folder. Your folder .git_filters should now contain the following files:
.git_filters/gaIdke-README
.git_filters/gaIdke-activate
.git_filters/gaIdke-post-checkout
.git_filters/gaIdke-post-commit
.git_filters/gaIdke-pre-commit
.git_filters/gaIdke-prepare-commit-msg
.git_filters/gaIdke-reset
.git_filters/gaIdke.clean
.git_filters/gaIdke.smudge
To activate GIT automatic $Id Keyword Expansion, run the script .git_filters/gaIdke-activate, which executes the following actions:
cd <project>/.git/hooks/
ln -sf ../../.git_filters/gaIdke-post-checkout post-checkout
ln -sf ../../.git_filters/gaIdke-post-commit post-commit
ln -sf ../../.git_filters/gaIdke-pre-commit pre-commit
ln -sf ../../.git_filters/gaIdke-prepare-commit-msg prepare-commit-msg
ln -sf ../../.git_filters/gaIdke-post-checkout post-merge
adds the following line to <project>/.gitattributes
* filter=gaIdke
adds the following [filter] lines to .git/config
or to ~/.gitconfig for all projects
[filter “gaIdke”]
clean = .git_filters/gaIdke.clean
smudge = .git_filters/gaIdke.smudge %f
To automate the activation of gaIdke, when your project is cloned by somebody else, you may want to add a safe call to .git_filters/gaIdke-activate to your “configure” script as described above in gaIdke-activate.
Justification and historical remarks
There has been much discussion about the pros and cons of Keyword Expansion and its absence in GIT. The attitude of the GIT developers is, that groups of files should always be looked at as a unit and at any point in time, a commit operation generates a snapshot of all the files in the project as they were at that point in time. Previous commits can be checked out – reconstituting the whole project as it was at that time. I agree that this is a very valid point and older VCSs suffered, because of their emphasis on versioning individual files only and not having useful facilities for handling changesets. SCCS and RCS as well as its offshoot CVS do not handle change sets automatically. They rely on tags, which are often forgotten and are nearly impossible to add later.
Because I have always felt changesets are extremely important, I developed scripts to automatically generate changesets for RCS or CVS in the early ’80s and these have been very successful to maintain consistency in my projects. Nevertheless, I feel strongly that there is a place for individual version numbers following more than a hundred-year-old tradition of drawing office practice in engineering, which can be described in a nutshell as follows:
- Each part to be manufactured is described by a drawing having a “name” and a “version-number”, which is incremented every time the drawing is changed and with signatures to provide an audit trail.
- Each assembly is described by a parts list (changeset) of drawing names with the current “version numbers” to build a functioning product. Such parts lists also have a “ version-number”, which is incremented every time the parts list is changed.
The outcome of this is, that engineers traditionally use both individual version numbers for parts and whole lists, and parts lists to describe changesets. Unfortunately, when Software Version Control Systems were introduced with SCCS and RCS in the early ’80s, programmers only had tools to do the automatic versioning of parts – that is individual files and no automatic support for changesets. Today GIT has come along and does the exact opposite: it provides automatic versioning for changesets only and does not provide monotonically increasing version numbers for individual files making up those changesets. To prove that this can be remedied I have written this set of hooks for GIT.
What the GIT developers forget is the fact that most programmers find it hard to always concentrate on the complete set of sources at all times and indeed they should not be forced to do so. When coding or merging one necessarily deals with one file although there might be cases where code in a number of files may be co-dependent and need to be edited together. But such a design is flawed in my view and should be avoided at all costs. The interface between functions or classes should be determined first and documented in a reasonably detailed comment block before coding even starts. Co-dependent functions should be gathered in one source file. Then each source file can be coded individually, concentrating with the mind on good algorithms for implementing the global pre-determined interface. What I am trying to say is, that it is good programming practice to get the details of the functions in one source file right by following the development of the changes made in those functions over a number of individual file versions. The version numbers of a source file provide a good mental trigger to the sequence of that development. I maintain that this is a valid workflow and programmers who choose to follow this workflow should be able to do so in GIT. Standard GIT enforces a different workflow and it may not always be comfortable. The global picture of all the files making up a project working together is very important, but it becomes important at a different time and possibly for different people (during system integration and commissioning).
As a trained engineer I was very much aware of this in the late ’80s and developed a method for automatically generating changesets for SCCS and later for RCS. This method relies on $Id strings with filename and version numbers embedded in every source file of a project. RCS automatically increments the minor version number in any $Id string of a file every time that file is committed (ci). If the code of any source file, which is compiled is organized in such a way, that the $Id string is embedded in a character array, which becomes part of a compiled object file and linked executable then one way to extract those $Id strings from such an executable is to execute ident(1) followed by sort -u and a small amount of formatting. A script I have written called mkv does just that. Here is an example of a small C executable ‘iCgpioPUD’ made up of just three source files:
ident iCgpioPUD # produces
$Id: bcm2835.h,v 1.19 2015/03/30 23:01:11 jw Exp $
$Id: iCgpioPUD.c,v 1.2 2015/04/11 09:30:33 jw Exp $
$Id: bcm2835.c,v 1.22 2015/03/29 08:14:44 jw Exp $
$Id: bcm2835.h,v 1.19 2015/03/30 23:01:11 jw Exp $
mkv iCgpioPUD # produces
$Id$
bcm2835.c 1.22 2015/03/29 08:14:44 jw Exp
bcm2835.h 1.19 2015/03/30 23:01:11 jw Exp
iCgpioPUD.c 1.2 2015/04/11 09:30:33 jw Exp
Note how bcm2835.h appears twice in the ‘ident’ output but only once in the mkv output, which is a change set or a parts list, a term used in engineering. A complementary script cov checks out all the source files in such a change set or parts list from the RCS repository. The crucial aspect of this method is, that every executable has the versioned parts list of all its source files embedded in it once the $Id string arrays have been set up in every source file:
static const char bcm2835_c[] =
“$Id$”;
which is changed after the first RCS commit (ci) to
static const char bcm2835_c[] =
“$Id: bcm2835.c,v 1.1 2014/05/05 08:55:00 jw Exp $”;
Over the years this work flow has proved very reliable, because it is automatic – one cannot forget to create the parts list or change set unlike a tag. It is very fast in tracking down bugs reported by customers by using diff between files extracted with mkv/cov from the customer’s version of a delivered executable and more recent versions.
CAVEAT: executables delivered to customers must be built from source files that have been checked in.
It seemed only natural to generate a comprehensive parts list xxx.v with mkv at every release point for project xxx and to also version xxx.v. As can be seen in the output above mkv already generates the $Id$ string for this to happen automatically. The version number of the xxx.v parts list is used by me as the version number of the release. Tagging, which is normally used for this purpose is not quite as useful as a versioned parts list xxx.v – different versions of such a parts list can be diffed to see immediately which source files have changed from one release to another.
Admittedly GIT deals with all the issues around change sets and is a great distributed version control system. That is why I am migrating to it now. For my projects I was able to use the regular versioned xxx.v parts lists, which define change sets in the 20 year history of my RCS projects to build accurate historical GIT repositories using ‘cvs-fast-export’ after massaging the RCS version files with commit-ids built from the change set information. Nevertheless, there are a number of good reasons to continue using automatically incremented version numbers in $Id strings for some files in GIT.
In most software projects there usually are a number of independent interpreted scripts consisting of single-file executables, which do not have to be built. Such scripts should be identified by an independent version number, if their operation is not directly related to other programs in a project. To do things correctly in the GIT way, such scripts should always be committed by themselves, so that the commit can be tagged with an individual version identifier. This is a lot to think of and I imagine is not regularly practised. For such cases, an automatically incremented version number can be very useful. Programs should also be in a position to report their version. It is very easy to do with $Ids – simply embed the $Id string in the –help or –version string. This also makes the $Id accessible to ident and mkv.
As mentioned earlier, there is a long engineering tradition of maintaining version numbers for all objects making up a product. The equivalent of a source file in engineering is a technical drawing. In 1957 I spent half a year in a drawing office as an engineering apprentice. The chief draughtsman impressed upon me the importance of documenting every change to a drawing, which was marked on the drawing by a change or version number, duly signed off by the draughtsman and after inspection by his boss. I also learned about parts lists, which had to be kept current to show the latest drawing version numbers which worked together. Any change to a parts list was also versioned. The whole process was supervised by the responsible engineer. When manufacturing a product in a factory it is essential that extreme care is taken to guarantee the working of the final product. Because the cost of failure is high, engineers are very disciplined about these matters.
A major problem with software development is the fact that the cost of failure appears, at first sight, to be relatively low – a few changed lines seem to fix most problems. Unless those changes are also documented and versioned it is very hard to find them again later. If it turns out that those changes have unforeseen side effects in the overall system they can become very costly, if the changes cannot be located quickly.
Up till the ’70s, programmers were rather slack with regard to backing up and versioning and it was not till the ’80s with the advent of SCCS and RCS that a need for versioned backups was felt necessary or indeed became possible. Here are a couple of war stories to give younger programmers a feel of how things were in those days.
-
- In 1975 I was chief engineer for a computer company in Germany that sold minicomputer based systems for commercial computing. I was also responsible for maintaining the 16 user time-sharing BASIC OS, which had been developed in assembler by a California based company. The system was rather fragile and I never received any sources so I was forced to do maintenance with a symbolic debugger and a disassembler, which I had written. I later found out that the California company had no up to date sources either, because their main developer used to make changes with the debugger using backpacks, which are new code written with the debugger in high memory. A JMP to the backpack would be inserted at the point of a bug. The end of the backpack had a JMP to a point past the bug. I was told on good authority that he would produce up to 15 backpacks in an afternoon, some of them being backpacks on top of backpacks. None of this code was ever written up as assembler source code. The discs containing the patched binaries were simply copied and sent to customers. (The backpacks were very obvious on disassembly). You can imagine how difficult it was for me to maintain that system, which was running payroll and other financial software packages written in BASIC at paying customer sites.
- In 1987 I started work with a PLC manufacturer. The group leader of the software department assured me that he could remember all the changes that had been made and that there was no need for backups. Admittedly backup memory was at a premium then. There was a major disaster a few weeks later. The Programming Software for the company’s Programmable Logic Controllers, which had been delivered to a large car manufacturer, turned out to be buggy. The customer did not report these bugs until 6 weeks after delivery. By this time the sources for the Programming Software had been modified and extended and were not in any state to be run. No backups had been kept and many days and nights were spent trying to reproduce the software, that had been delivered to the customer, from memory and then work out what was going wrong. SCCS, which I had already been using for a number of years at another company was gratefully accepted after this incident. I also developed the strategy of source file parts lists based on engineering type version numbers and the tools to generate them automatically at this time.
GIT does force programmers to version each change by committing them and forces them to document the change by supplying a commit message. With standard GIT any changes are identified by the following entities:
-
- The SHA-1 hash of the commit (usually in short form). This is the primary identifier of a complete changeset or snapshot of all files at the time of the commit. Everybody agrees that the hash string is useful to extract files but is no good for human consumption. I cannot imagine anyone trying to identify a version in their mind with a hash string – be it short or long. Also, hash strings cannot be used for sorting commits.
- The date-time of the commit. This string is also a unique identifier of a commit (assuming no two commits in one project are done in the same second). But again a date-time string to the nearest second is rather cumbersome and does not fit easily into something humans can and want to use to compare two versions in their mind. Date-time strings do have the virtue of allowing the sorting of commits into the order they occurred.
- The obligatory commit message the committer has to provide. This text may be very useful, but it does depend very much on the discipline of the individual user. It can be searched for in the ‘git log’ output and thus lead a later investigator to a specific commit. Extra data about a commit is available as a comment in the commit message before it is presented to the committer, but it is mostly not un-commented.
- Optionally any commit may be identified by a ‘tag’. The text of the tag may be nearly any string. For obvious reasons, this is often chosen to be an engineering type, full-stop separated version number, which everyone is used to and which the mind handles easily for identifying and comparing a sequence of evolving products. A useful feature of GIT is the fact that tags may be applied to a commit at any time, giving users the means to apply memorable names to an otherwise nearly nameless commit entity (Nameless to humans).
- As a rule, the actual files that have changed and which have been committed together in any particular commit are not recorded by GIT. The list can only be obtained indirectly by doing a ‘git diff –name-only’ between two commits. Since such a list is not available directly trying to grep a set of such lists becomes a major exercise in ‘on the fly’ shell scripting, which I imagine would be beyond many programmers. I will show how such a list can easily be embedded in each commit message. The lists can then be easily grepped in the ‘git log’.
I accept the GIT workflow, which is to produce combined diffs or patch sets of modifications in all files which are committed together. This set provides the history of a certain idea cast into code, which may be spread over a number of files. This workflow does require a lot of discipline though to make sure that commits are done before any new ideas are started (commit often cannot be stressed enough).
Concluding remarks
Special care has been taken that $Id strings imported from legacy RCS, CVS or SVN repositories are not modified by ‘clean’ or ‘smudge’. This has been done so that files checked out from GIT historical commits imported from RCS, CVS or SVN are identical to the same files checked out from RCS, CVS or SVN and diff correctly with the GIT historical archive. $Id: strings from SVN have not been tested, but should be OK. An example of $Id$ expansion in the SVN book is:
$Id: calc.c 148 2006-07-28 21:30:43Z sally $
The only place where a legacy $Id string is changed to a clean GIT $Id string, which can subsequently be smudged is in ‘pre-commit’, where the minor version number (the whole version number in the case of SVN) is incremented to continue the sequence.
I said at the beginning of this proposal that my scripts would update $Id strings in a similar way to that which is carried out in RCS, CVS or SVN. This is not quite correct. In all the legacy VCSs the file version number is an attribute of each file in the respective repository. In a commit (ci) operation this file version number is incremented but in the case of RCS and CVS the old $Id string with the un-incremented version number and the old date is stored in the repository text. The updated version number and correct commit date are not visible in a version string until the file is checked out again (co). SVN is more careful and stores the unadorned (cleaned) version string $Id$ in the repository with every commit. Most GIT implementations of ‘clean’ and ‘smudge’ follow the SVN pattern and make no attempt to generate a numeric version number. They simply adorn the $Id string with the smudge information.
The fundamental problem is, that GIT does no have a numeric file version number. Therefore it cannot be generated or incremented in ‘smudge’ because an independent version number for each file just does not exist. The only reasonably way to implement a file version number in GIT is to generate or increment it in ‘pre-commit’ and store it with its up to date file name in the repository, ready for the next commit. One advantage of this strategy is, that after each commit the correct file name and correct updated version number is immediately visible in the $Id strings in files listed with gitk. Only the specific GIT attributes SHA-1 hash, date and author name are added to the working copy by ‘smudge’ on checkout.
An issue that is sometimes raised is the problem that occurs if a file with $Id versions is modified in separate branches and subsequently needs to be merged. The version numbers in each branch will be incremented independently for every file change and commit in that branch. When those files are merged, the $Id strings will conflict, but that conflict can be resolved quite easily – just choose the version applicable to the current branch. This could be done automatically with a ‘pre-merge’ hook, but so far GIT does not have one. So the inconvenience of an occasional manual merge conflict resolution for $Id versions from different branches is the only non-automatic action imposed on users of this package.
The following was put forward on StackOverflow to justify GIT not being able to maintain individual sequential revision numbers:
The key thing to understand is that GIT cannot have revision numbers – think about the decentralized nature. If users A and B are both committing to their local repositories, how can GIT reasonably assign a sequential revision number? A has no knowledge of B before they push/pull each other’s changes.
My answer to that is, if A and B have both made changes to the same file and have committed those changes in their local GIT repositories, they will strike trouble when they push those changes to a common repository – say GitHub. Whoever pushes first – say A – will have their changes and incremented version number accepted, but when B tries to push their committed changes this will not be possible because of content descent differences – not because of version number differences, which will actually be the same. B will first have to fetch A’s changes and merge them into his own changed version. B will then have to commit those changes locally which will increment the file version number again, which will make it one higher than A’s version. After this B will be able to push. This leads to the following scenario:
Local A GIT Local B GIT GitHub
before any changes $Id xx.c 1.4 $Id xx.c 1.4 $Id xx.c 1.4
local commit by A $Id xx.c 1.5
local commit by B $Id xx.c 1.5 different to A
push by A $Id xx.c 1.5 $Id xx.c 1.5
attempted push by B $Id xx.c 1.5 fails
because not descended from current version in GitHub
fetch by B $Id xx.c 1.5 same as A
merge/commit by B $Id xx.c 1.6
push by B $Id xx.c 1.6 $Id xx.c 1.6
fetch by A $Id xx.c 1.6 $Id xx.c 1.6 $Id xx.c 1.6
This scenario shows that B will have an extra local commit containing an erroneous change. This would be the same with and without version number incrementing. But the final merged and pushed sequence of changes has correctly incremented file version numbers.
There is nothing special about the version number text in the $Id string. It can be modified manually to show any version the user deems appropriate. One manual change that is often made is to increment the major version number and start again with a low minor version eg 1.47 ==> 2.0. (Remember to keep the minor version in the file about to be committed one less than what you want it to be after committing, which will be 2.1).
sempre que tenho um horário vago eu venho me informar em seu site .
os posts são sempre muito bem escritos e simples de entender .
Até breve
Whenever I have a vacant time I come to inform me on their website.
the posts are always very well written and simple to understand.
see you later
Seus artigos são incríveis . Como eu posso deixar meu email para ser informado quando houver
novas matérias ?
Your articles are amazing. How can I leave my email to be informed when there is
new materials ?
If you email me a short summary of what you do and preferably your experience with “GIT keyword expansion” or “immediate C” to immediateC@gmail.com, I will keep you posted.
Unfortunately I do not speak Portuguese, only English and German. But I can always translate a Portuguese email.
Hi John, thanks for the comprehensive article! I’m a complete beginner with GIT and all the codes seem to me a maze 🙂 Hopefully I’ll learn how to work with GIT soon. Cheers.
very interesting, have looked a long time for such facility